6. Parameter learning in Spiking Neural Networks#
Author: Christian Pehle
As we have already seen in Introduction to spiking systems Neuron models come with parameters, such as membrane time constants, which determine their dynamics. While those parameters are often treated as arbitrarily treated constants and therefore hyperparameters in a machine learning context, more recently it has become clear that it can be benefitial to treat them as parameters. In this notebook, we will first learn how to initialise a network of LIF neurons with distinct, but fixed time constants and voltage thresholds and then how to incorporate them into the optimisation. As we will see, this is largely facilitated by the pre-existing ways of treating parameters in PyTorch.
import norse.torch as norse
import torch
import matplotlib.pyplot as plt
6.1. Defining a Network of LIF Neurons with varying membrane time-constants#
A population of recurrently connected LIF neurons can be instantiated in Norse as follows:
from norse.torch import LIFRecurrentCell
m = LIFRecurrentCell(input_size=200, hidden_size=100)
m
LIFRecurrentCell(input_size=200, hidden_size=100, p=LIFParameters(tau_syn_inv=tensor(200.), tau_mem_inv=tensor(100.), v_leak=tensor(0.), v_th=tensor(1.), v_reset=tensor(0.), method='super', alpha=tensor(100.)), autapses=False, dt=0.001)
As you can see the LIFParameters are initialised to some default values. It is easy enough to instead sample these values from a given distribution. While we will use a random normal distribution here, a more appropriate choice would be for example a lognormal distribution, as this would guarantee that the inverse membrane time constant remains positive, which is an essential requirement. Here we just choose the standard deviation in such a way, that a negative value would be very unlikely.
import numpy as np
counts, bins = np.histogram(norse.LIFParameters().tau_mem_inv + 20*torch.randn(100))
plt.hist(bins[:-1], bins, weights=counts, histtype='step')
plt.xlabel('$\\tau_{m}^{-1}$ [ms]')
Text(0.5, 0, '$\\tau_{m}^{-1}$ [ms]')
The parameters of a PyTorch module can be accesses by invoking the parameters method. In the case of the LIFRecurrentCell those are the recurrent and input weight matrices. Note how both tensors have requires_grad=True and that the LIFParameters do not appear. This is because none of the tensors entering the LIFParameters have been registered as a PyTorch Parameter.
list(m.parameters())
[Parameter containing:
tensor([[ 0.0917, -0.3016, -0.0810, ..., -0.0725, 0.0058, -0.0734],
[-0.1709, -0.1772, -0.1558, ..., 0.0042, -0.1564, -0.2113],
[-0.1474, 0.1708, -0.0464, ..., -0.0300, 0.1009, -0.0204],
...,
[-0.0197, -0.0429, -0.0831, ..., 0.0720, -0.0731, 0.1546],
[ 0.2321, -0.1730, -0.0681, ..., 0.2246, -0.2462, 0.1287],
[ 0.0767, 0.1800, 0.0838, ..., 0.0579, -0.2331, -0.0282]],
requires_grad=True),
Parameter containing:
tensor([[ 0.0000, 0.0269, -0.2374, ..., -0.0730, -0.1753, 0.2046],
[ 0.1771, 0.0000, 0.1860, ..., -0.0433, 0.0914, 0.1529],
[-0.1721, 0.1623, 0.0000, ..., 0.0083, 0.0010, 0.2725],
...,
[-0.1044, 0.0096, 0.1179, ..., 0.0000, -0.1140, 0.0828],
[ 0.1375, 0.0721, 0.1459, ..., 0.0878, 0.0000, 0.0673],
[ 0.0122, -0.2929, -0.0939, ..., -0.0627, 0.0153, 0.0000]],
requires_grad=True)]
The easiest way to rectify this situation is to define an additional torch.nn.Module and explicitely register the inverse membrane time constant and threshold as a parameter.
class ParametrizedLIFRecurrentCell(torch.nn.Module):
def __init__(self, input_size, hidden_size):
super(ParametrizedLIFRecurrentCell, self).__init__()
self.tau_mem_inv = torch.nn.Parameter(norse.LIFParameters().tau_mem_inv + 20*torch.randn(hidden_size))
self.v_th = torch.nn.Parameter(0.5 + 0.1 * torch.randn(hidden_size))
self.cell = norse.LIFRecurrentCell(input_size=input_size, hidden_size=hidden_size,
p = norse.LIFParameters(
tau_mem_inv = self.tau_mem_inv,
v_th = self.v_th,
alpha = 100,
)
)
def forward(self, x, s = None):
return self.cell(x, s)
m = ParametrizedLIFRecurrentCell(200, 100)
m
ParametrizedLIFRecurrentCell(
(cell): LIFRecurrentCell(
input_size=200, hidden_size=100, p=LIFParameters(tau_syn_inv=tensor(200.), tau_mem_inv=Parameter containing:
tensor([107.6515, 75.8270, 91.3901, 109.7474, 131.0936, 102.1687, 108.9974,
112.1108, 89.5503, 104.9164, 99.3130, 133.6543, 85.6361, 100.7905,
46.9257, 123.4043, 104.7868, 112.8862, 93.6564, 164.1430, 64.7086,
81.7677, 79.9042, 133.8024, 108.8173, 84.7685, 126.6351, 94.8440,
91.8692, 104.7018, 96.1917, 128.8073, 124.7022, 75.1250, 84.9478,
106.6687, 89.0486, 99.0763, 121.2750, 64.6533, 111.3764, 100.4910,
60.7458, 95.5237, 86.2169, 87.9412, 107.8178, 70.8849, 111.8520,
94.6805, 95.5359, 111.2908, 70.0749, 111.0684, 87.0124, 87.7380,
122.6774, 66.4563, 104.1748, 98.1120, 110.9409, 98.6834, 74.0883,
76.2126, 88.2449, 110.8336, 131.0593, 129.2769, 67.2605, 116.9765,
98.5443, 118.0189, 116.1124, 105.0717, 83.2675, 88.8886, 109.5207,
51.4418, 103.5416, 98.3810, 111.2044, 113.8318, 93.0837, 137.7964,
110.0572, 95.9072, 120.1097, 102.3509, 115.7312, 120.0014, 96.7311,
62.7951, 135.2355, 148.5360, 125.8353, 103.9729, 91.0144, 121.6775,
138.3222, 75.4974], requires_grad=True), v_leak=tensor(0.), v_th=Parameter containing:
tensor([0.6338, 0.5769, 0.4537, 0.2291, 0.4272, 0.7191, 0.5009, 0.4774, 0.4444,
0.4624, 0.3245, 0.5556, 0.3811, 0.6210, 0.7051, 0.6925, 0.6418, 0.4892,
0.5359, 0.3778, 0.6870, 0.5278, 0.6603, 0.4889, 0.4744, 0.6926, 0.6323,
0.5269, 0.4834, 0.5946, 0.5205, 0.4398, 0.5432, 0.3719, 0.5262, 0.5473,
0.5984, 0.4345, 0.5470, 0.3051, 0.4174, 0.6331, 0.3088, 0.4318, 0.4054,
0.6322, 0.3358, 0.5477, 0.5528, 0.4983, 0.4483, 0.4672, 0.6736, 0.6030,
0.4507, 0.4816, 0.3819, 0.5392, 0.3398, 0.4185, 0.5485, 0.4923, 0.4509,
0.6243, 0.4524, 0.5003, 0.3465, 0.3663, 0.5988, 0.3140, 0.3504, 0.4603,
0.3925, 0.3178, 0.2901, 0.5616, 0.3442, 0.5255, 0.4138, 0.4251, 0.6578,
0.4250, 0.5146, 0.4473, 0.5080, 0.4501, 0.6041, 0.4750, 0.6032, 0.6816,
0.5619, 0.5772, 0.6030, 0.4492, 0.6023, 0.6729, 0.5598, 0.2717, 0.7205,
0.4596], requires_grad=True), v_reset=tensor(0.), method='super', alpha=tensor(100)), autapses=False, dt=0.001
)
)
The inverse membrane time constant and the threshold value now also appears as parameters:
list(m.parameters())
[Parameter containing:
tensor([107.6515, 75.8270, 91.3901, 109.7474, 131.0936, 102.1687, 108.9974,
112.1108, 89.5503, 104.9164, 99.3130, 133.6543, 85.6361, 100.7905,
46.9257, 123.4043, 104.7868, 112.8862, 93.6564, 164.1430, 64.7086,
81.7677, 79.9042, 133.8024, 108.8173, 84.7685, 126.6351, 94.8440,
91.8692, 104.7018, 96.1917, 128.8073, 124.7022, 75.1250, 84.9478,
106.6687, 89.0486, 99.0763, 121.2750, 64.6533, 111.3764, 100.4910,
60.7458, 95.5237, 86.2169, 87.9412, 107.8178, 70.8849, 111.8520,
94.6805, 95.5359, 111.2908, 70.0749, 111.0684, 87.0124, 87.7380,
122.6774, 66.4563, 104.1748, 98.1120, 110.9409, 98.6834, 74.0883,
76.2126, 88.2449, 110.8336, 131.0593, 129.2769, 67.2605, 116.9765,
98.5443, 118.0189, 116.1124, 105.0717, 83.2675, 88.8886, 109.5207,
51.4418, 103.5416, 98.3810, 111.2044, 113.8318, 93.0837, 137.7964,
110.0572, 95.9072, 120.1097, 102.3509, 115.7312, 120.0014, 96.7311,
62.7951, 135.2355, 148.5360, 125.8353, 103.9729, 91.0144, 121.6775,
138.3222, 75.4974], requires_grad=True),
Parameter containing:
tensor([0.6338, 0.5769, 0.4537, 0.2291, 0.4272, 0.7191, 0.5009, 0.4774, 0.4444,
0.4624, 0.3245, 0.5556, 0.3811, 0.6210, 0.7051, 0.6925, 0.6418, 0.4892,
0.5359, 0.3778, 0.6870, 0.5278, 0.6603, 0.4889, 0.4744, 0.6926, 0.6323,
0.5269, 0.4834, 0.5946, 0.5205, 0.4398, 0.5432, 0.3719, 0.5262, 0.5473,
0.5984, 0.4345, 0.5470, 0.3051, 0.4174, 0.6331, 0.3088, 0.4318, 0.4054,
0.6322, 0.3358, 0.5477, 0.5528, 0.4983, 0.4483, 0.4672, 0.6736, 0.6030,
0.4507, 0.4816, 0.3819, 0.5392, 0.3398, 0.4185, 0.5485, 0.4923, 0.4509,
0.6243, 0.4524, 0.5003, 0.3465, 0.3663, 0.5988, 0.3140, 0.3504, 0.4603,
0.3925, 0.3178, 0.2901, 0.5616, 0.3442, 0.5255, 0.4138, 0.4251, 0.6578,
0.4250, 0.5146, 0.4473, 0.5080, 0.4501, 0.6041, 0.4750, 0.6032, 0.6816,
0.5619, 0.5772, 0.6030, 0.4492, 0.6023, 0.6729, 0.5598, 0.2717, 0.7205,
0.4596], requires_grad=True),
Parameter containing:
tensor([[ 0.1260, 0.2575, -0.0652, ..., -0.0386, -0.0514, 0.0880],
[ 0.1172, 0.0411, 0.0746, ..., -0.0893, -0.0898, -0.0205],
[ 0.1116, -0.0248, 0.2825, ..., -0.2597, -0.0076, 0.0737],
...,
[-0.0145, 0.1551, -0.0784, ..., 0.0405, 0.1092, -0.2261],
[-0.1494, -0.1946, -0.1108, ..., 0.2603, -0.1176, 0.2275],
[-0.0409, 0.0966, 0.1104, ..., -0.1157, -0.2011, -0.0241]],
requires_grad=True),
Parameter containing:
tensor([[ 0.0000, 0.1548, 0.0879, ..., -0.0995, -0.3868, 0.1231],
[ 0.1915, 0.0000, -0.0372, ..., -0.0753, 0.0830, 0.1178],
[ 0.1607, 0.0428, 0.0000, ..., 0.0506, -0.1978, 0.1937],
...,
[-0.0181, -0.0755, 0.0090, ..., 0.0000, -0.0606, -0.1115],
[-0.1452, 0.1591, -0.1814, ..., -0.0600, 0.0000, 0.0761],
[-0.1547, -0.0992, -0.0467, ..., 0.2122, 0.0525, 0.0000]],
requires_grad=True)]
6.2. Toy Example: Training a small recurrent SNN on MNIST#
In order to demonstrate training on an example task, we turn to MNIST. The training and testing code here is adopted from the training notebook on MNIST and serves as an illustration. We do not necessarily expect there to be a great benefit in optimising the time-constants and threshold in this example.
6.2.1. Dataset Loading#
import torchvision
BATCH_SIZE = 256
transform = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,)),
]
)
train_data = torchvision.datasets.MNIST(
root=".",
train=True,
download=True,
transform=transform,
)
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=BATCH_SIZE,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST(
root=".",
train=False,
transform=transform,
),
batch_size=BATCH_SIZE
)
0%| | 0.00/9.91M [00:00<?, ?B/s]
1%| | 98.3k/9.91M [00:00<00:12, 777kB/s]
4%|▍ | 393k/9.91M [00:00<00:06, 1.59MB/s]
16%|█▌ | 1.61M/9.91M [00:00<00:01, 4.87MB/s]
66%|██████▌ | 6.55M/9.91M [00:00<00:00, 17.0MB/s]
100%|██████████| 9.91M/9.91M [00:00<00:00, 15.9MB/s]
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 429kB/s]
0%| | 0.00/1.65M [00:00<?, ?B/s]
6%|▌ | 98.3k/1.65M [00:00<00:02, 755kB/s]
24%|██▍ | 393k/1.65M [00:00<00:00, 1.64MB/s]
97%|█████████▋| 1.61M/1.65M [00:00<00:00, 5.11MB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 4.17MB/s]
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 4.06MB/s]
6.2.2. Model Defitinition#
For simplicity we are considering a simple network with a single hidden layer of recurrently connected neurons.
from norse.torch import LICell
class SNN(torch.nn.Module):
def __init__(self,
input_features,
hidden_features,
output_features,
recurrent_cell
):
super(SNN, self).__init__()
self.cell = recurrent_cell
self.fc_out = torch.nn.Linear(hidden_features, output_features, bias=False)
self.out = LICell()
self.input_features = input_features
def forward(self, x):
seq_length, batch_size, _, _, _ = x.shape
s1 = so = None
voltages = []
for ts in range(seq_length):
z = x[ts, :, :, :].view(-1, self.input_features)
z, s1 = self.cell(z, s1)
z = self.fc_out(z)
vo, so = self.out(z, so)
voltages += [vo]
return torch.stack(voltages)
class Model(torch.nn.Module):
def __init__(self, encoder, snn, decoder):
super(Model, self).__init__()
self.encoder = encoder
self.snn = snn
self.decoder = decoder
def forward(self, x):
x = self.encoder(x)
x = self.snn(x)
log_p_y = self.decoder(x)
return log_p_y
6.2.3. Training and Test loop#
Both the training and test loop are independent of the model or dataset that we are using, in practice you should however probably use a more sophisticated version as they don’t take care of parameter checkpoints or other concerns.
from tqdm.notebook import tqdm, trange
def train(model, device, train_loader, optimizer, epoch, max_epochs):
model.train()
losses = []
for (data, target) in tqdm(train_loader, leave=False):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
mean_loss = np.mean(losses)
return losses, mean_loss
def test(model, device, test_loader, epoch):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += torch.nn.functional.nll_loss(
output, target, reduction="sum"
).item() # sum up batch loss
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100.0 * correct / len(test_loader.dataset)
return test_loss, accuracy
from norse.torch import ConstantCurrentLIFEncoder
def decode(x):
x, _ = torch.max(x, 0)
log_p_y = torch.nn.functional.log_softmax(x, dim=1)
return log_p_y
T = 32
LR = 0.002
INPUT_FEATURES = 28*28
HIDDEN_FEATURES = 100
OUTPUT_FEATURES = 10
EPOCHS = 5
if torch.cuda.is_available():
DEVICE = torch.device("cuda")
else:
DEVICE = torch.device("cpu")
def run_training(model, optimizer, epochs = EPOCHS):
training_losses = []
mean_losses = []
test_losses = []
accuracies = []
torch.autograd.set_detect_anomaly(True)
for epoch in trange(epochs):
training_loss, mean_loss = train(model, DEVICE, train_loader, optimizer, epoch, max_epochs=EPOCHS)
test_loss, accuracy = test(model, DEVICE, test_loader, epoch)
training_losses += training_loss
mean_losses.append(mean_loss)
test_losses.append(test_loss)
accuracies.append(accuracy)
print(f"final accuracy: {accuracies[-1]}")
return model
6.2.4. Model Evaluation#
With all of this boilerplate out of the way we can define our final model and run training for a number of epochs (10 by default). If you are impatient you can decrease that number to 1-2. With the default values, the result will be a test accuracy of >95%, that is nothing to write home about.
model = Model(
encoder=ConstantCurrentLIFEncoder(
seq_length=T,
),
snn=SNN(
input_features=INPUT_FEATURES,
hidden_features=HIDDEN_FEATURES,
output_features=OUTPUT_FEATURES,
recurrent_cell=ParametrizedLIFRecurrentCell(
input_size=28*28,
hidden_size=100
)
),
decoder=decode
).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
tau_mem_inv_before = model.snn.cell.cell.p.tau_mem_inv.cpu().detach().numpy()
v_th_before = model.snn.cell.cell.p.v_th.cpu().detach().numpy()
model_after = run_training(model, optimizer, epochs=10)
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[17], line 1
----> 1 model_after = run_training(model, optimizer, epochs=10)
Cell In[14], line 9, in run_training(model, optimizer, epochs)
5 accuracies = []
7 torch.autograd.set_detect_anomaly(True)
----> 9 for epoch in trange(epochs):
10 training_loss, mean_loss = train(model, DEVICE, train_loader, optimizer, epoch, max_epochs=EPOCHS)
11 test_loss, accuracy = test(model, DEVICE, test_loader, epoch)
File /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages/tqdm/notebook.py:312, in tnrange(*args, **kwargs)
310 def tnrange(*args, **kwargs):
311 """Shortcut for `tqdm.notebook.tqdm(range(*args), **kwargs)`."""
--> 312 return tqdm_notebook(range(*args), **kwargs)
File /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages/tqdm/notebook.py:234, in tqdm_notebook.__init__(self, *args, **kwargs)
232 unit_scale = 1 if self.unit_scale is True else self.unit_scale or 1
233 total = self.total * unit_scale if self.total else self.total
--> 234 self.container = self.status_printer(self.fp, total, self.desc, self.ncols)
235 self.container.pbar = proxy(self)
236 self.displayed = False
File /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages/tqdm/notebook.py:108, in tqdm_notebook.status_printer(_, total, desc, ncols)
99 # Fallback to text bar if there's no total
100 # DEPRECATED: replaced with an 'info' style bar
101 # if not total:
(...) 105
106 # Prepare IPython progress bar
107 if IProgress is None: # #187 #451 #558 #872
--> 108 raise ImportError(WARN_NOIPYW)
109 if total:
110 pbar = IProgress(min=0, max=total)
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
tau_mem_inv_after = model_after.snn.cell.cell.p.tau_mem_inv.cpu().detach().numpy()
v_th_after = model_after.snn.cell.cell.p.v_th.cpu().detach().numpy()
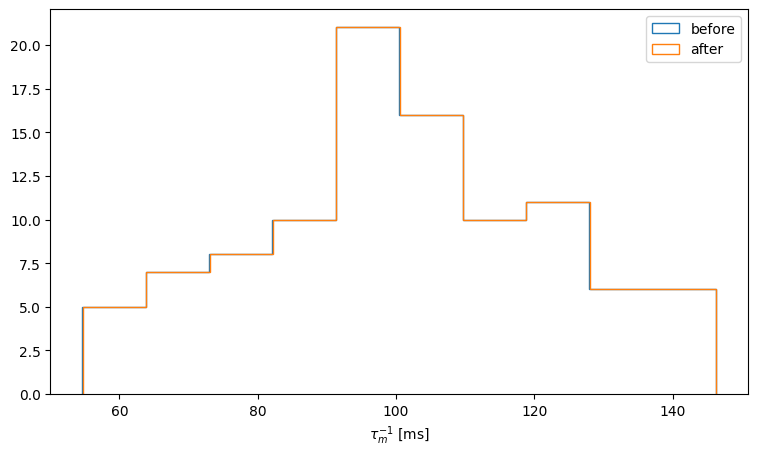
We can plot the distribution of inverse membrane timeconstants before and after the training:
counts, bins = np.histogram(tau_mem_inv_before)
fig, ax = plt.subplots(figsize=(9,5))
ax.hist(bins[:-1], bins, weights=counts, histtype='step', label='before')
counts, bins = np.histogram(tau_mem_inv_after)
ax.hist(bins[:-1], bins, weights=counts, histtype='step', label='after')
ax.set_xlabel('$\\tau_{m}^{-1}$ [ms]')
ax.legend()
<matplotlib.legend.Legend at 0x7f74b561dd30>
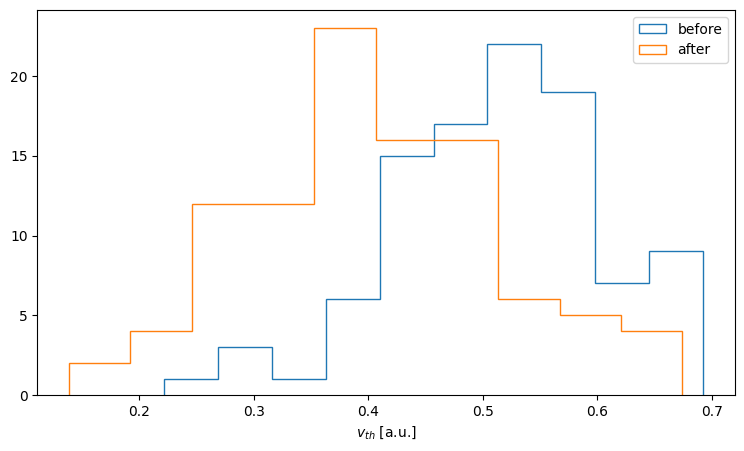
Similarly we can plot the distribution of membrane threshold voltages before and after optimisation:
counts, bins = np.histogram(v_th_before)
fig, ax = plt.subplots(figsize=(9,5))
ax.hist(bins[:-1], bins, weights=counts, histtype='step', label='before')
counts, bins = np.histogram(v_th_after)
ax.hist(bins[:-1], bins, weights=counts, histtype='step', label='after')
ax.set_xlabel('$v_{th}$ [a.u.]')
ax.legend()
<matplotlib.legend.Legend at 0x7f74ae9f3e00>
6.3. Conclusions#
This concludes this tutorial, as we have seen incorporating neuron parameters into the optimisation in Norse mainly requires knowledge of the PyTorch internals. At the moment that optimisation is also only supported for the surrogate gradient implementation and not while using the discretised adjoint implementation. This is not a fundamental limitation though and support for neuron parameter gradients could be added.
Several publications have recently explored optimising neuron parameters to both demonstrate that the resulting time constant distributions more closely resembled ones measured in biological cells and advantages in ML applications. As always the challenge to practically demonstrating the advantage of incorporating neuron parameters into the optimisation is doing careful and controlled experiments and choosing the right tasks. While this notebook demonstrates the general technique it does take some shortcuts:
Optimisation works best if the scale of the values to be optimised is in an appropriate range. This is not the case here for the inverse time constant, which has a value of > 100. A more sophisticated approach would take this into account by for example generating this parameter from an appropriately scaled initial value.
Similarly we have chosen a rather naive initialisation of both the threshold and inverse membrane time constant. More careful initialisation would for example involve sampling from a distribution with guaranteed positive samples.
Finally we haven’t demonstrated any benefit of jointly optimising neuron parameters and synaptic weights.