norse.torch.module.encode.PopulationEncoder#
- class norse.torch.module.encode.PopulationEncoder(out_features: int, scale: int | ~torch.Tensor = None, kernel: ~typing.Callable[[~torch.Tensor], ~torch.Tensor] = <function gaussian_rbf>, distance_function: ~typing.Callable[[~torch.Tensor, ~torch.Tensor], ~torch.Tensor] = <function euclidean_distance>)[source]#
Encodes a set of input values into population codes, such that each singular input value is represented by a list of numbers (typically calculated by a radial basis kernel), whose length is equal to the out_features.
Population encoding can be visualised by imagining a number of neurons in a list, whose activity increases if a number gets close to its “receptive field”.
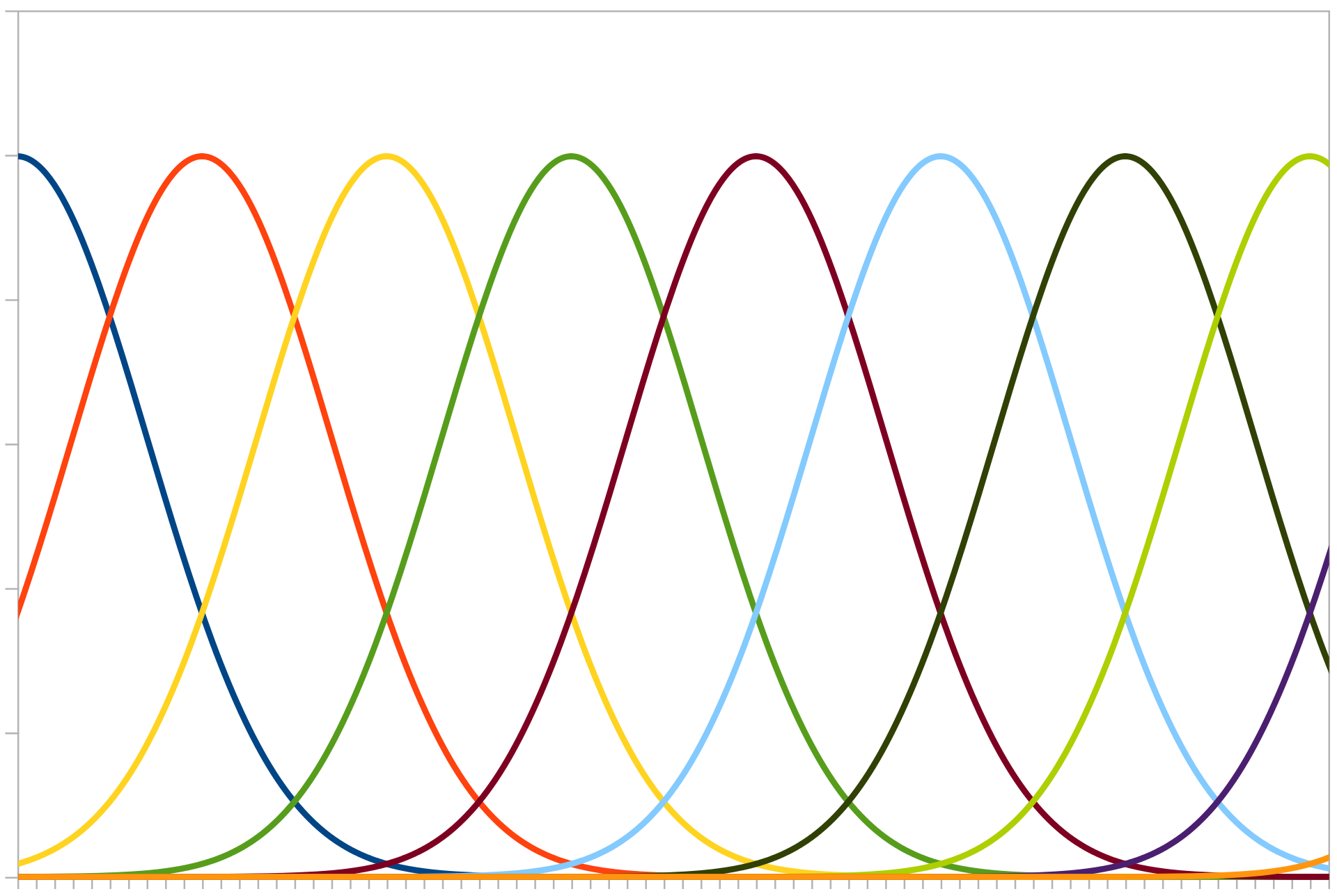
Fig. 1 Gaussian curves representing different neuron “receptive fields”. Image credit: Andrew K. Richardson.#
- Example:
>>> data = torch.as_tensor([0, 0.5, 1]) >>> out_features = 3 >>> PopulationEncoder(out_features).forward(data) tensor([[1.0000, 0.8825, 0.6065], [0.8825, 1.0000, 0.8825], [0.6065, 0.8825, 1.0000]])
- Parameters:
out_features (int): The number of output per input value scale (torch.Tensor): The scaling factor for the kernels. Defaults to the maximum value of the input.
Can also be set for each individual sample.
- kernel: A function that takes two inputs and returns a tensor. The two inputs represent the center value
(which changes for each index in the output tensor) and the actual data value to encode respectively.z Defaults to gaussian radial basis kernel function.
distance_function: A function that calculates the distance between two numbers. Defaults to euclidean.
- __init__(out_features: int, scale: int | ~torch.Tensor = None, kernel: ~typing.Callable[[~torch.Tensor], ~torch.Tensor] = <function gaussian_rbf>, distance_function: ~typing.Callable[[~torch.Tensor, ~torch.Tensor], ~torch.Tensor] = <function euclidean_distance>)[source]#
Initialize internal Module state, shared by both nn.Module and ScriptModule.
Methods
__init__(out_features[, scale, kernel, ...])Initialize internal Module state, shared by both nn.Module and ScriptModule.
add_module(name, module)Add a child module to the current module.
apply(fn)Apply
fnrecursively to every submodule (as returned by.children()) as well as self.bfloat16()Casts all floating point parameters and buffers to
bfloat16datatype.buffers([recurse])Return an iterator over module buffers.
children()Return an iterator over immediate children modules.
compile(*args, **kwargs)Compile this Module's forward using
torch.compile().cpu()Move all model parameters and buffers to the CPU.
cuda([device])Move all model parameters and buffers to the GPU.
double()Casts all floating point parameters and buffers to
doubledatatype.eval()Set the module in evaluation mode.
extra_repr()Return the extra representation of the module.
float()Casts all floating point parameters and buffers to
floatdatatype.forward(input_tensor)Define the computation performed at every call.
get_buffer(target)Return the buffer given by
targetif it exists, otherwise throw an error.get_extra_state()Return any extra state to include in the module's state_dict.
get_parameter(target)Return the parameter given by
targetif it exists, otherwise throw an error.get_submodule(target)Return the submodule given by
targetif it exists, otherwise throw an error.half()Casts all floating point parameters and buffers to
halfdatatype.ipu([device])Move all model parameters and buffers to the IPU.
load_state_dict(state_dict[, strict, assign])Copy parameters and buffers from
state_dictinto this module and its descendants.modules()Return an iterator over all modules in the network.
mtia([device])Move all model parameters and buffers to the MTIA.
named_buffers([prefix, recurse, ...])Return an iterator over module buffers, yielding both the name of the buffer as well as the buffer itself.
named_children()Return an iterator over immediate children modules, yielding both the name of the module as well as the module itself.
named_modules([memo, prefix, remove_duplicate])Return an iterator over all modules in the network, yielding both the name of the module as well as the module itself.
named_parameters([prefix, recurse, ...])Return an iterator over module parameters, yielding both the name of the parameter as well as the parameter itself.
parameters([recurse])Return an iterator over module parameters.
register_backward_hook(hook)Register a backward hook on the module.
register_buffer(name, tensor[, persistent])Add a buffer to the module.
register_forward_hook(hook, *[, prepend, ...])Register a forward hook on the module.
register_forward_pre_hook(hook, *[, ...])Register a forward pre-hook on the module.
register_full_backward_hook(hook[, prepend])Register a backward hook on the module.
register_full_backward_pre_hook(hook[, prepend])Register a backward pre-hook on the module.
register_load_state_dict_post_hook(hook)Register a post-hook to be run after module's
load_state_dict()is called.register_load_state_dict_pre_hook(hook)Register a pre-hook to be run before module's
load_state_dict()is called.register_module(name, module)Alias for
add_module().register_parameter(name, param)Add a parameter to the module.
register_state_dict_post_hook(hook)Register a post-hook for the
state_dict()method.register_state_dict_pre_hook(hook)Register a pre-hook for the
state_dict()method.requires_grad_([requires_grad])Change if autograd should record operations on parameters in this module.
set_extra_state(state)Set extra state contained in the loaded state_dict.
set_submodule(target, module[, strict])Set the submodule given by
targetif it exists, otherwise throw an error.share_memory()state_dict(*args[, destination, prefix, ...])Return a dictionary containing references to the whole state of the module.
to(*args, **kwargs)Move and/or cast the parameters and buffers.
to_empty(*, device[, recurse])Move the parameters and buffers to the specified device without copying storage.
train([mode])Set the module in training mode.
type(dst_type)Casts all parameters and buffers to
dst_type.xpu([device])Move all model parameters and buffers to the XPU.
zero_grad([set_to_none])Reset gradients of all model parameters.
Attributes
T_destinationcall_super_initdump_patchestraining
{kind=link}